* 부스트캠프 "모두를 위한 컴퓨터 과학"의 강의 내용을 기록한 게시물입니다.
https://www.boostcourse.org/cs112/lecture/118999
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
알고리즘
전 강의에서 숫자, 글자, 색깔 등을 컴퓨터가 이해할 수 있는 2진법으로 표현 것을 배웠습니다.
이 것은 입력(input)에 해당하는 것입니다.

이제는 출력(output)에 대해 이야기를 해볼까요?
그럼 어떻게 입력(input)에서 출력(output)을 얻을 수 있을까요?
컴퓨팅은 입력을 받아 그 입력을 처리한 후 출력하는 과정입니다.
알고리즘은 입력(input)에서 받은 자료를 출력(output)형태로 만드는 처리 과정을 뜻합니다.
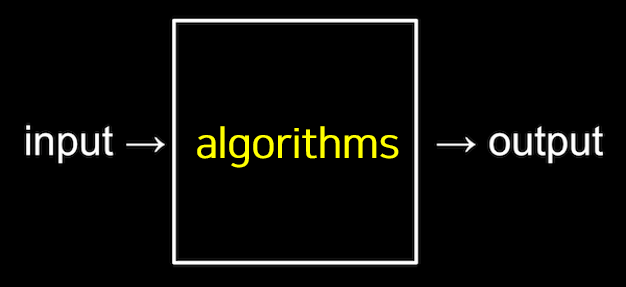
즉, 알고리즘이란 입력값을 출력값의 형태로 바꾸기 위해 어떤 명령들이 수행되어야 하는지에 대한 규칙들의 순서적 나열입니다. (어려운 용어가 나오지만 억지로 이해하기 보다 우선 넘어가시고, 아래의 예시를 통해 이해를 해주세요.)
이러한 일련의 순서적 규칙들을 어떻게 나열하는지에 따라 알고리즘의 종류가 달라집니다.
같은 출력값이라도 알고리즘에 따라 출력을 하기까지의 시간이 다를 수 있습니다.
정확한 알고리즘
예를 들어, 전화번호부에서 Mike Smith를 찾는 일을 한다고 합시다.
전화번호부를 집어 들고 첫 페이지를 펼친 후 Mike Smith가 그 페이지에 있는지 찾습니다.
없으면 그 다음 페이지에서 찾습니다.
Mike Smith 를 찾을 때까지 혹은 전화번호부가 끝날 때까지 이것을 반복합니다.
하지만 언젠가는 Mike Smith 가 전화번호부에 있다면 이 알고리즘을 통해 Mike Smith 를 찾을 수 있을 것입니다.
알고리즘의 평가할 때는 정확성도 중요하지만, 효율성도 중요합니다.
효율성은 작업을 완료하기까지 얼마나 시간과 노력을 덜 들일 수 있는지에 대한 것입니다.
여러분들이 보시기에도 한 번에 한 페이지씩 보는 알고리즘은 정확하지만, 매우 오래걸리고 비효율적인 알고리즘일 것입니다.
한 번에 두 페이지를 넘기게끔 하여 알고리즘을 개선할 수 있습니다.
하지만 이 알고리즘을 그대로 사용한다면 Mike Smith가 있는 페이지가 그냥 넘어갈 수도 있으니 주의해야 할 것입니다.
이럴 때는 이전 페이지를 확인하면 되지만 이 알고리즘마저도 이 문제를 해결하기에 가장 효율적이지는 않습니다.
정확하고 효율적인 알고리즘
이번에는 더 직관적이고 효율적인 알고리즘을 적용하여 Mike Smith를 찾아봅시다.
먼저, 전화번호부 가운데를 폅니다. 만약 Mike Smith가 그 페이지에 있다면 우리 알고리즘은 끝납니다.
없다면, 전화번호부가 이름순으로 정렬되어 있으므로 우리는 Mike Smith가 지금 페이지보다 앞부분에 있는지 뒷부분에 있는지 알고 있습니다.
그러므로 책의 절반을 버릴 수 있게 되고 나머지 절반에 대해 똑같은 알고리즘을 수행합니다.
한 페이지가 남을 때까지 계속 수행합니다.
마지막에 남은 한 페이지에는 Mike Smith의 이름이 있거나 없거나 둘 중 하나일 겁니다.
이 알고리즘은 기존 알고리즘보다 더 효율적입니다.
만약 기존 전화번호부가 100페이지고, 100페이지가 또 추가되어 200페이지가 되었다고 생각해봅시다.
한장 한장 넘기는 첫 번째 알고리즘은 100번의 페이지를 더 넘겨야 하지만, 절반씩 줄어드는 두 번째 알고리즘은 단 1번의 절차만 더 수행하면 됩니다.
단 한 번의 동작으로 200페이지의 반인 100페이지가 사라지기 때문입니다.
앞서 말씀드린 '알고리즘이란 입력값을 출력값의 형태로 바꾸기 위해 어떤 명령들이 수행되어야 하는지에 대한 규칙들의 순서적 나열'이라는 정의를 다시 보겠습니다.
우리는 Mike Smith를 전화번호부에서 찾기 위해 어떤 명령들이 수행되어야 하는지에 대해 두 가지 알고리즘을 찾아봤습니다.
첫 번째 알고리즘은 한 장을 넘긴 다음 또 한 장 넘기는 규칙들의 순서적 나열이었고,
두 번째 알고리즘은 반을 줄이고, 다음 또 반을 줄이는 규칙들의 순서적 나열이었습니다.
이제 앞서 나온 알고리즘의 정의에 대해 느낌이 오시나요?
의사코드
위와 같은 알고리즘은 아래와 같은 의사코드라는 방식으로 보다 명료하게 정리할 수 있습니다.
의사코드는 필요한 행동이나 조건을 잘 설정하여 컴퓨터가 수행해야 하는 일을 절차적으로 파악할 수 있게 도와줍니다.
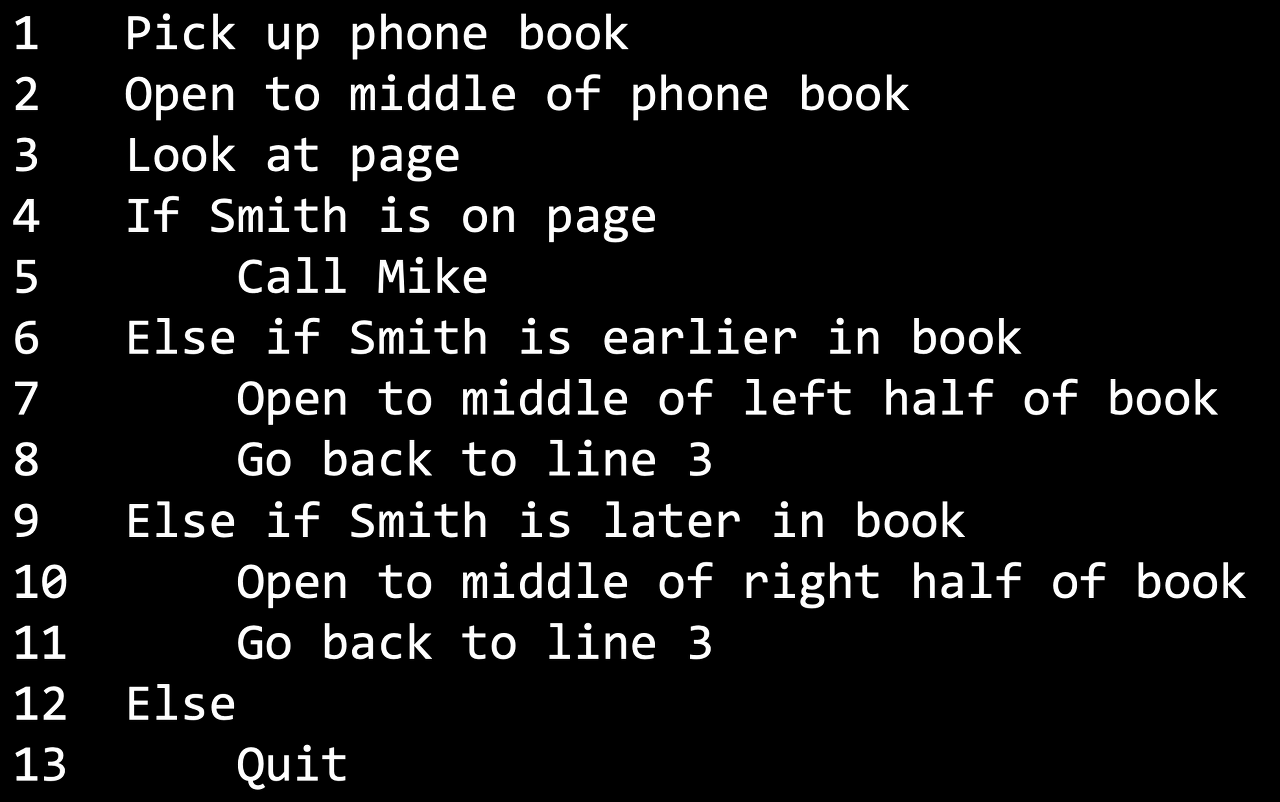
(중간중간 들여쓰기가 되어있는 부분은 종속 관계를 나타내는데 자세한 설명은 나중에 나옵니다.)
- 전화번호부를 집어 든다
- 전화번호부의 중간을 편다
- 페이지를 본다
- 만약 Mike Smith가 페이지에 있으면
- Mike Smith에게 전화한다.
- 그렇지 않고 만약 Mike Smith가 앞 페이지에 있으면
- 앞 페이지의 절반을 편다
- 3번째 줄부터 다시 실행한다
- 그렇지 않고 만약 Mike Smith가 뒷 페이지에 있으면
- 뒷 페이지의 절반을 편다
- 3번째 줄부터 다시 실행한다
- 그러지 않으면
- 그만둔다
의사코드를 보면 여러분들도 한 번씩 들어봤을 C언어나 파이썬과 같은 언어에서도 볼 수 있는 여러가지 공통점이 있습니다.
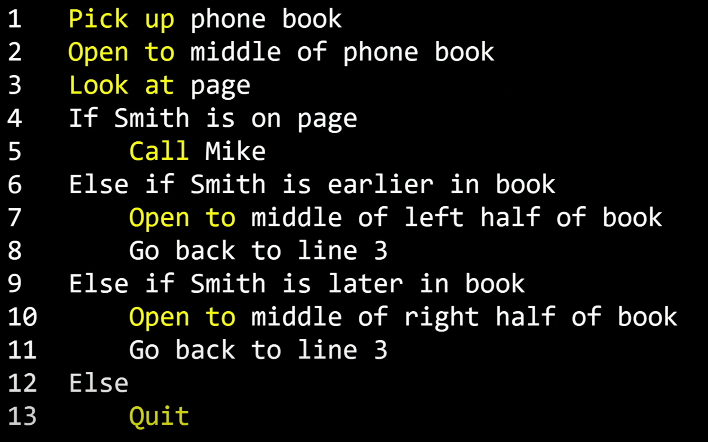
노란색으로 강조된 부분들은 앞으로 함수(functions)로 불립니다.
함수는 컴퓨터에게 이 경우에는 사람에게 무엇을 할지 알려주는 동사와 같습니다.
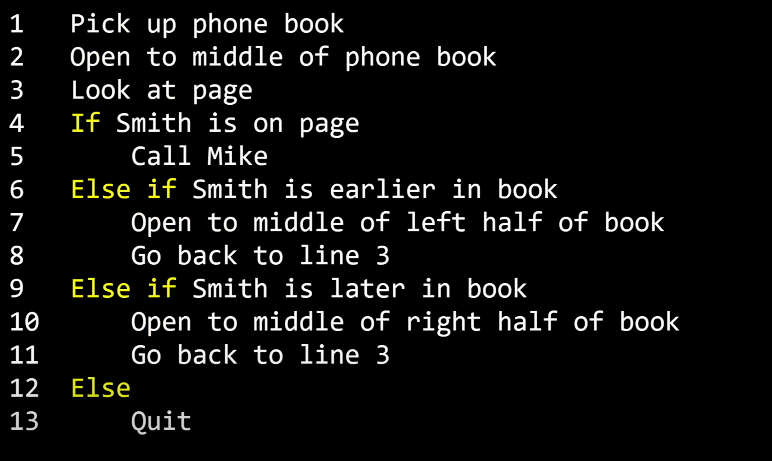
다음으로 노란색으로 강조된 부분들은 조건이라고 부를 것입니다.
이 것은 여러 선택지 중 하나를 고르는 것입니다.
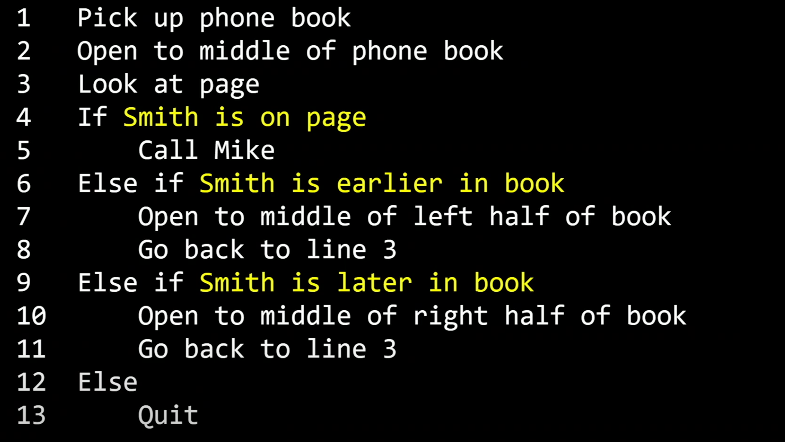
앞서 말한 결정을 내리기 위한 질문이 필요합니다. 이것을 불리언(Boolean)이라고 합니다.
답이 Yes(예) 또는 No(아니오) 혹은 True(참) 또는 False(거짓)으로 나오는 아니면 2진법에서 0또는 1로 나오는 질문을 뜻합니다.
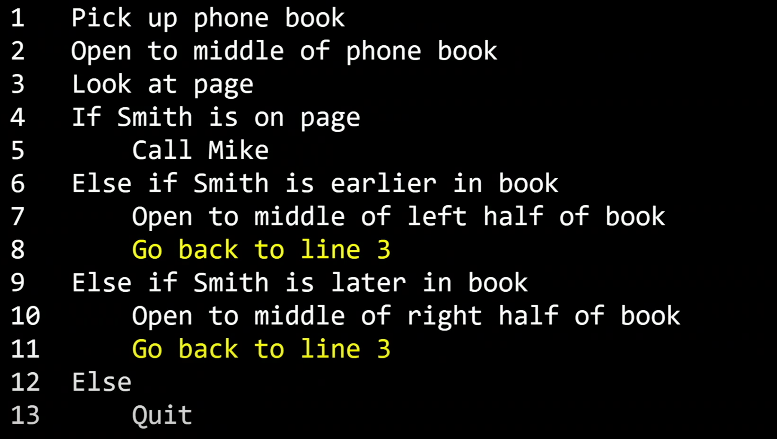
마지막으로 노란색으로 강조된 부분은 루프(loop)라고 합니다.
이 것은 뭔가를 계속해서 반복하는 순환입니다.
'컴퓨터 사이언스 Computer Science > [강의] 모두를 위한 컴퓨터 과학' 카테고리의 다른 글
| [모두를 위한 컴퓨터 과학] 1-1. 이진법 (0) | 2022.08.17 |
|---|

댓글